Introducing CLUTRR
Compositional Language Understanding with Text based Relational Reasoning
Motivation
Question Answering (QA) has recently gained popularity as the major domain of testing reasoning in text. The literature thus contains a deluge of Question Answering (QA) datasets to choose from. These datasets test the system’s ability to extract factual answers from the text. However, there are growing concerns regarding the ability of Natural Language Understanding (NLU) models to generalize - both in a systematic and robust way. Adding to that, the recent dominance of large pre-trained language models (such as BERT, Devlin et al. 2018) on many NLU benchmarks including QA suggests that the primary difficulty in these datasets are about incorporating the statistics of the language, or the syntax of the language, rather than pure reasoning.
We want to develop systems which perform reasoning inductively,
i.e. not only by pure extraction of text facts but by performing a
higher-order reasoning and drawing conclusions based on evidence.
Ideally, we also want the systems to generalize on unseen
distributions, as well as be robust to adversarial attacks. To
facilitate that research, we present our diagnostic suite “CLUTRR”.
Overview
Our benchmark suite CLUTRR contains a large set of semi-synthetic
stories involving hypothetical families. Given a story, the goal is to
infer the relationship between two family members, whose relationship is
not explicitly mentioned.

To solve this task, an agent must extract the logical rules governing the composition of the relationships (e.g. the transitivity of the sibling relations). The benchmark allows us to test the learning agent’s ability for systematic generalization by testing on stories that contain unseen combinations of logical rules. It also allows us to precisely test for the various forms of model robustness by adding different kinds of superfluous noise facts to the stories.
Dataset Construction
To derive a dataset which provides an effective way to test generalization and robustness, we looked into classical Logic. Inductive Logic Programming (ILP) is a vast field of work which tries to solve the exact problem of inductively inferring rules from a given set of data, and one of the classical examples in the field is deducing kinship relations. For example, given the facts:
- “Alice is Bob’s mother”
- “Jim is Alice’s father”
one can infer with reasonable certainty that:
- “Jim is Bob’s grandfather”
While this may appear trivial to us, it is a challenging task to design models that can learn from the data to induce the logical rules necessary to make such inferences. For the above example, the system needs to learn the rule:
\[ [\texttt{grandfatherOf},X,Y] \vdash [[\texttt{fatherOf},X,Z], [\texttt{fatherOf}, Z,Y]] \]
In ILP, a subset of the above rules was provided as background knowledge to the system. The system then used to generate higher-order of rules by recombining existing rules and validating it with the given data.
Inspired by this classic task, we set upon building a QA task where each story is grounded with a logical rule. The core idea being that each story would describe a set of natural language relations, and the target is to infer the relationship between two entities whose relationship is not explicitly stated in the story.
To generate such a story, we first design a knowledge base (KB) of valid relation compositions for the kinship world. In practice, we used a set of 15 simple rules by carefully avoiding possible ambiguities (such as relations derived from in-laws). Using these set of rules, we generate the underlying kinship graph, i.e. a graph containing the kinship relations about a toy family.
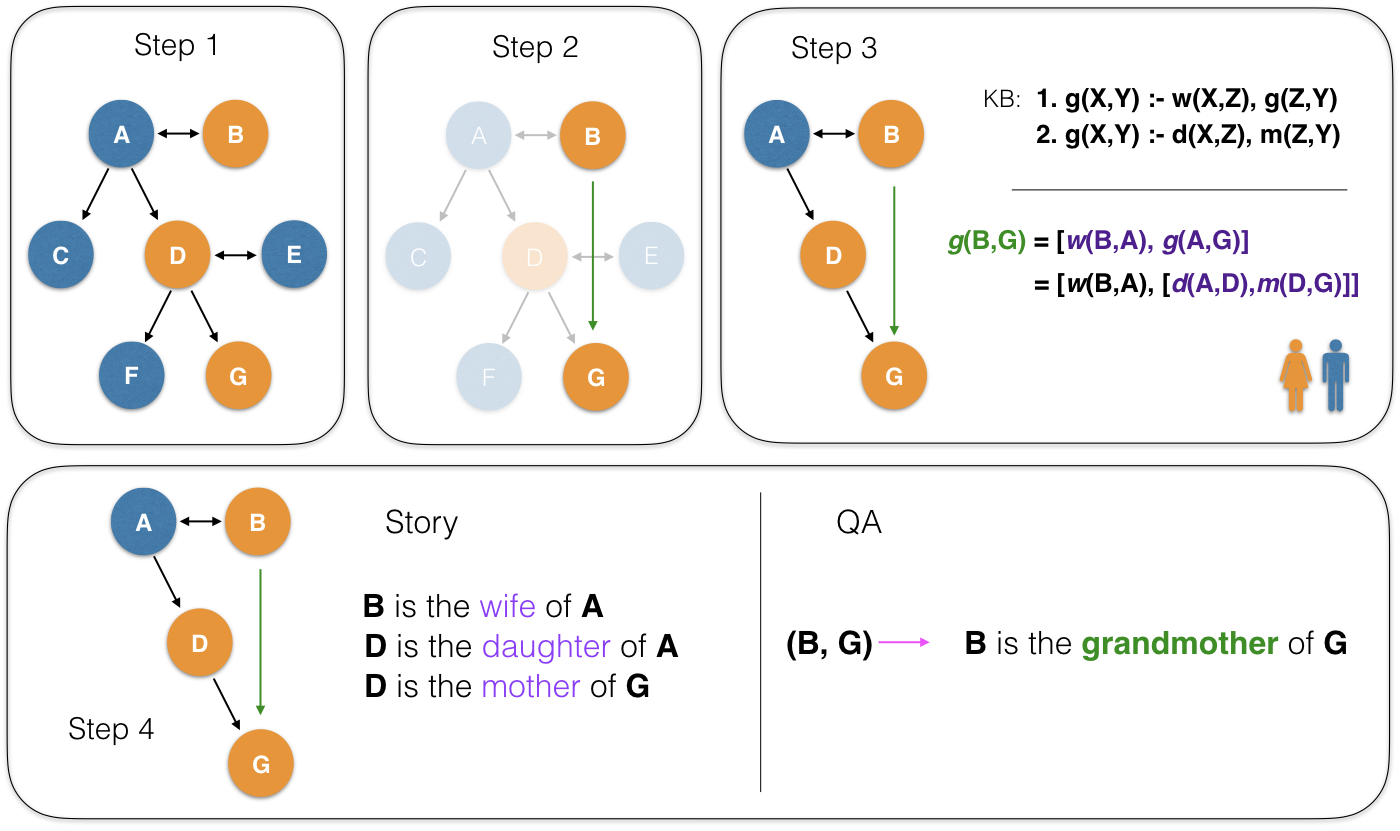
From this kinship graph, we sample an edge which becomes our target relation to predict. Recall, since we used logical rules to derive this graph, a path or walk in the graph from a source to sink constitutes a valid logical rule or clause. We simply sample such a path of length \(k\), where \(k\) is the tunable parameter for the data generation.
Adding Language
Given this sampled path \(G_p\), we aim to convert this into semi-synthetic text. The naive way would be to just replace each edge in the path by a placeholder text explaining the relationship between them. Consider the example provided in the above figure. The path \[ B \rightarrow A \rightarrow D \rightarrow G \] can be replaced by the following text:
- \[ B \rightarrow A \] : B is the wife of A
- \[ A \rightarrow D \] : D is the daughter of A
- \[ D \rightarrow G \] : D is the mother of G
However, as you can see it already, this ends up to a very artificial dataset having less linguistic variation. Thus, to reduce the artificial flavor, we asked Amazon Mechanical Turkers to provide us paraphrases for entire sampled paths. The above example then converts to:
A went to shopping with her wife B at the local grocery store. His daughter, D, is visiting them for thanksgiving with her daughter G.
This adds extra levels of complexity in the task : co-reference resolution, dependency parsing and named entity recognition.
In practice, it became difficult to collect paraphrases of all possible paths of unbounded lengths. Turkers need active attention to paraphrase each path, and futhermore increasing path length increases the number of combinations of relations, leading to larger and larger number of unique paths. Thus, we collected paraphrases for all possible combinations till \(k=3\), and we re-use paraphrases to stitch together a story. We collect 6,016 unique paraphrases with an average of 19 paraphrases for every possible logical clause of length \(k = 1,2,3\).
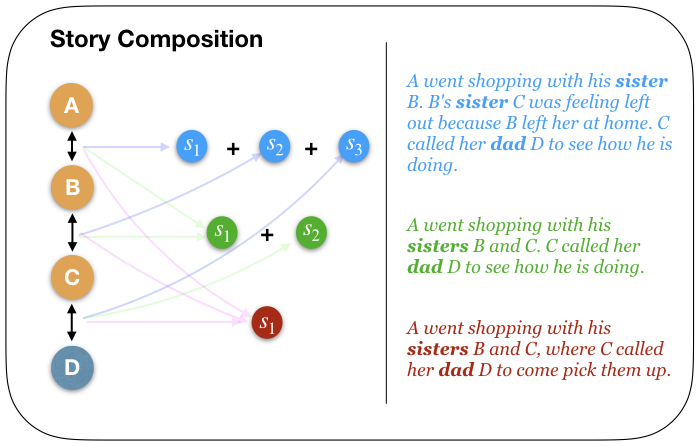
From the above example, we see that the stochasticity of dataset generation provides multiple ways of stitching paraphrases to generate stories. While the topicality of different paraphrases might impact coherence of the story, the stitched story remains logically grounded with respect to kinship relations, and maintains the aspects of co-reference resolution.
Question & Task
Thus, given a logically grounded story \(S\) , the question simply boils down to the target edge, i.e. the source and sink. We refrained from using a “natural language” question following the insightful discoveries of Kaushik & Lipton, (EMNLP 2018), thus our question is a tuple of entities, where the order defines the exact kinship relation. Finally, the task is to classify the correct relation among 22 kinship relations.
Systematic Generalization
Systematic Generalization is the ability of a model to solve tasks on a test distribution which is different than the training distribution, while the test distribution has been derived from the same production rules as that of the training. Chomsky (1957), Montague (1970), Lake & Baroni (2018) define the term as:
The algebraic capacity to understand and produce a potentially infinite number of novel combinations from known components.
This topic is so involved it requires a separate blog post on its own. In simple terms, we want our NLU models to generalize on out-of-domain data distributions in a particular task. However, restricting the scope of out-of-domain is critical : we cannot expect a model trained on sentence entailments in English to generalize on Bengali for instance.
In our dataset, we provide a simple way to test out-of-domain (OOD) generalization : by evaluating on stories with different logical compositions of the relations. To understand the composition of a single relation, the model needs to learn all binary compositions which lead to the particular relation. (e.g. father + father = grandfather, and sibling + grandfather = grandfather). Once it does, the model should be able to generalize on unseen compositions by re-using the learnt composition functions. The test distribution is still derived from the same production rules, as in the same knowledge base (KB).
OOD Generalization can be also be achieved in the level of the underlying language in our dataset. Recall, we have used a set of placeholders collected from AMT to construct the stories : we can thus have a subset of the collected paraphrases being held out for testing. This enables linguistic generalization, which explicitly restricts models to memorize on syntactical artifacts of the dataset.
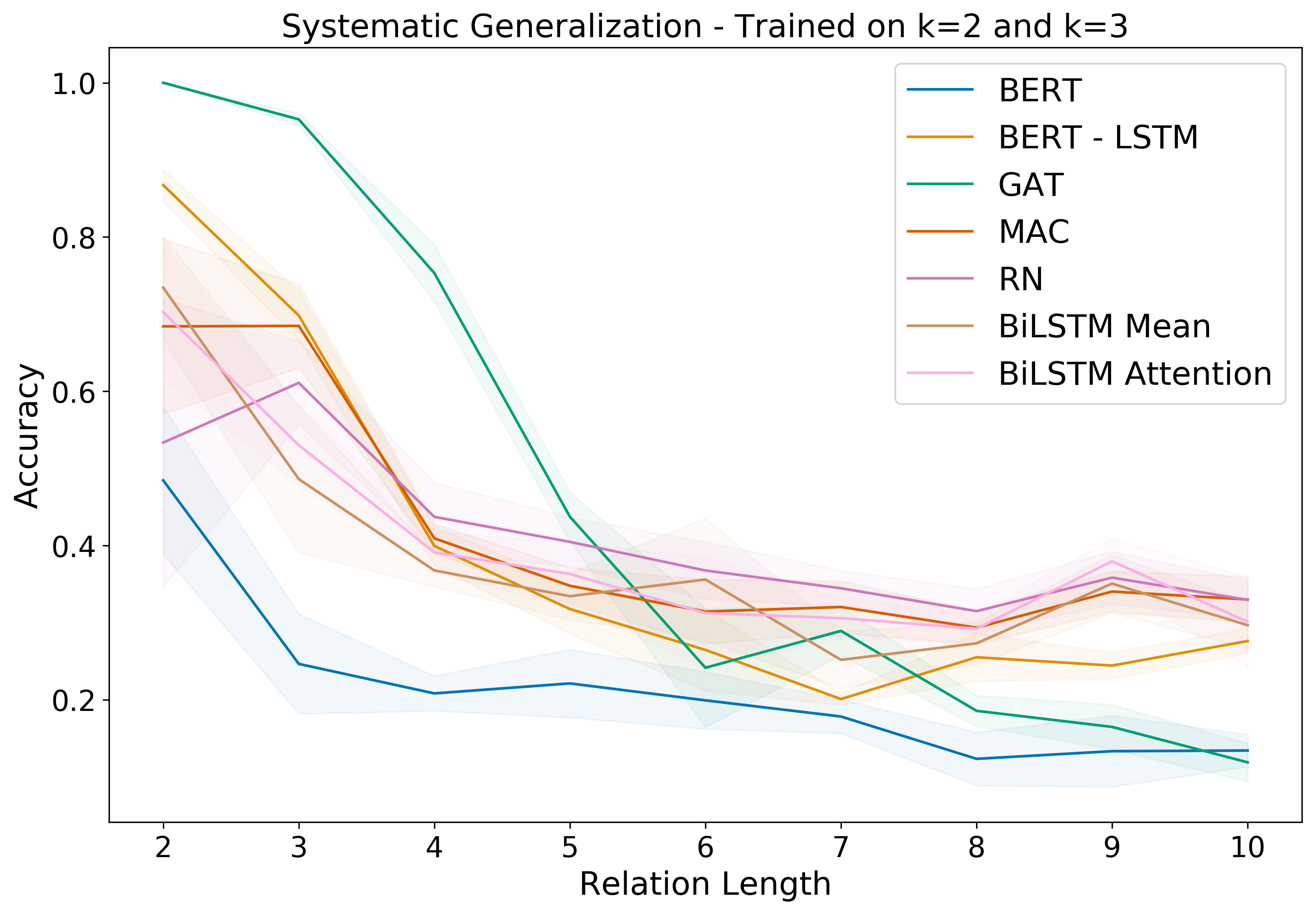
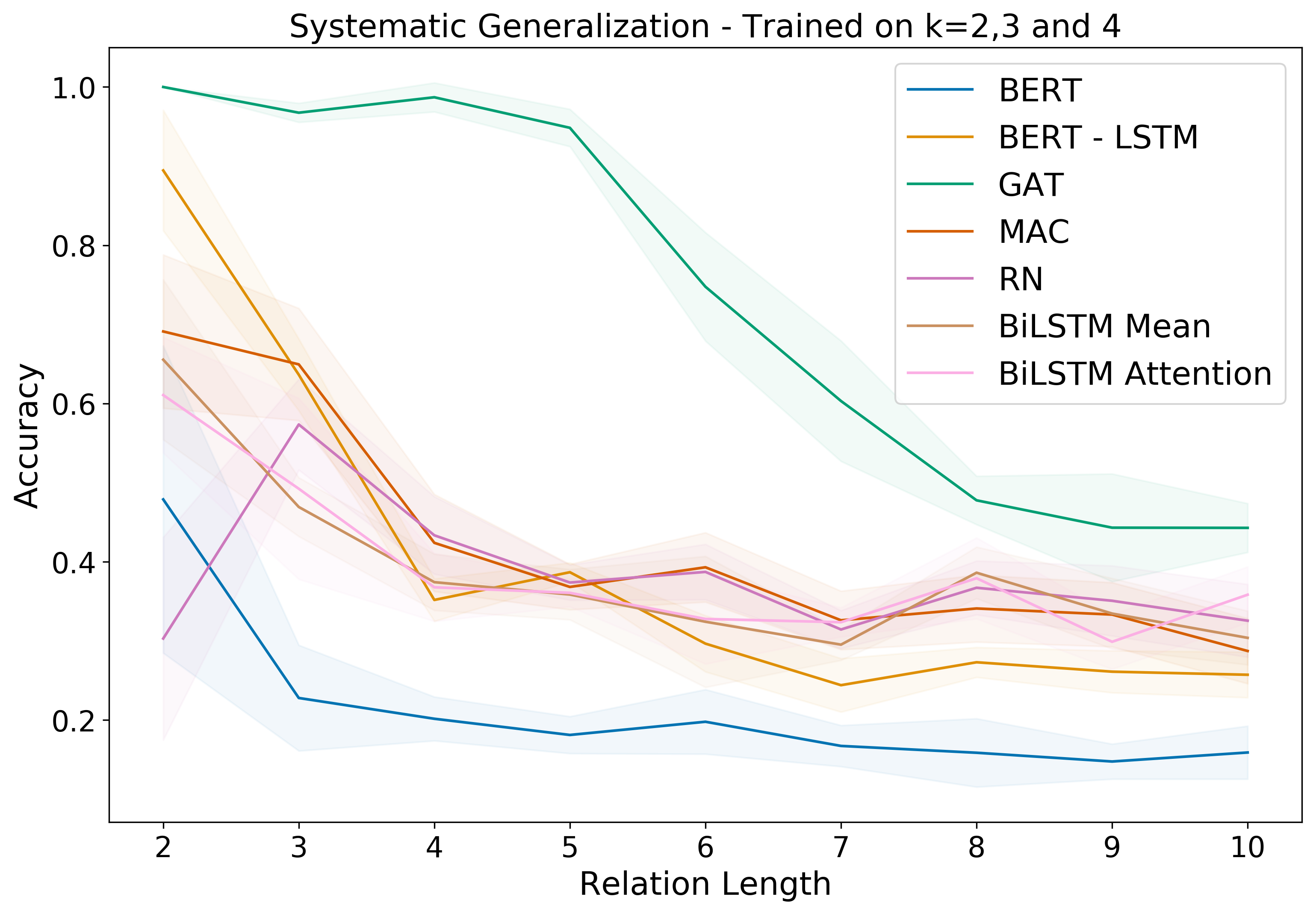
We perform experiments with a combination of logical and linguistic generalization with two types of baselines : NLU models such as BiLSTM, Relation Networks (Santoro et al, 2017), MAC (Hudson et al, 2018), and pretrained language model such as BERT (Devlin et al. 2018); and Graph Attention Networks (GAT) (Veličković et al, 2018) working on the symbolic graphs underlying the stories. We observe that Systematic Generalization is a hard problem with performance decrease across all models as we increase the length of the logical clause \(k\). This highlights the challenge of “zero-shot” systematic generalization (Lake & Baroni, 2018; Sodhani et al. 2018). The performance of GAT is significantly better than all NLU baselines, indicating that most NLU systems focus on the syntax rather than abstract reasoning.
Robust Reasoning
The modular setup of CLUTRR allows us to diagnose models for
robustness, another critical form of generalization. Since all
underlying stories have a logically valid path \(G_p\), we can add
paths which are not relevant to resolution of the task. Concretely, we
can add three types of noise:
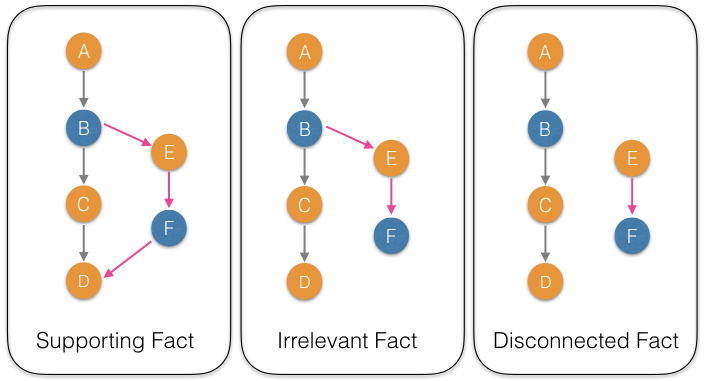
- Supporting facts: A path which originates and ends within \(G_p\). These are extra facts which are not needed to answer the query, but can be used, in principle, to construct alternative reasoning paths.
- Irrelevant facts: A dangling path which originates from \(G_p\) but has a different sink. This is essentially a distractor which the model has to carefully stray away while reasoning for the given query.
- Disconnected facts: A path which neither originates nor ends in \(G_p\). This constitute an unrelated noise in the data.
Thus, we can have multiple train/test scenarios to evaluate robustness in highly granular level by combination of the above facts with the clean setup. We perform experiments with the same set of baselines while fixing the length \(k\) of the clauses to \((2,3)\). We observe that overall GAT outperforms NLU models significantly on a range of train/test scenarios. This showcases the benefit of structure and inductive bias for performing abstract reasoning.
We observe a couple of interesting trends as well:
- NLU models perform better when testing on supporting and irrelevant facts while being trained on a noise-less setup. This suggests NLU models actually benefit from more content which may provide linguistic cues, irrelevant of the reasoning pathway.
- GAT model performs poorly on the above setup which shows that it is sensitive to changes involving cycles - it cannot understand the need of cycles of they are not trained with one. However, GAT performs significantly better when trained with cycles.
Key Takeaways
- We need structure / inductive biases in our models to perform better on Generalization and Robust Reasoning
- NLU models must try to represent the inductive bias or structure internally
- Systematic Generalization is hard, and we need more research in representing compositional and modular networks.
- Logic provides a provable way to devise datasets for tasks involving abstract reasoning
Closing Remarks
CLUTRR provides a fine-grained modular way to test the reasoning
capabilities of NLU systems - by asking the fundamental questions of
Systematic Generalization and Robustness. We found that existing NLU
systems perform relatively poorly on these questions compared to a
graph-based model which has symbolic inputs. This highlights the gap
that remains between machine reasoning models that work on unstructured
text and structured inputs.
Paper
Please read our paper for more information regarding dataset construction and experiments.
Code
Our code is available at https://github.com/facebookresearch/clutrr, where we will be adding possible extensions and applications of the dataset.
Acknowledgements
I have a long list of people to thank for supporting this project. Will Hamilton, Joelle Pineau (my superb advisors); Shagun Sodhani, Jin Dong (my awesome collaborators); Jack Urbanek, Stephen Roller (for numerous help with ParlAI); Adina Williams, Dzmitry Bahdanau, Prasanna Parthasarathy, Harsh Satija (for discussions and feedback); Abhishek Das, Carlos Eduardo Lassance, Gunshi Gupta, Milan Aggarwal, Rim Assouel, Weiping Song, and Yue Dong (for feedback on the manuscript); many anonymous Amazon Mechanical Turk participants for providing paraphrases; Sumana Basu, Etienne Denis, Jonathan Lebensold, and Komal Teru (for providing reviews on the dataset); Sanghyun Yoo, Jehun Jeon and Dr Young Sang Choi of Samsung Advanced Institute of Technology (SAIT) (for supporting the workshop version of the paper); Facebook AI Research (FAIR) (for providing extensive compute resources). This research was supported by the Canada CIFAR Chairs in AI program.
Citation
If you want to use our dataset in your research, please consider citing our paper:
@article{sinha2019clutrr,
Author = {Koustuv Sinha and Shagun Sodhani and Jin Dong and Joelle Pineau and William L. Hamilton},
Title = {CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text},
Year = {2019},
journal = {Empirical Methods of Natural Language Processing (EMNLP)},
arxiv = {1908.06177}
}
If you like the idea and want to collaborate on exciting applications, feel free to drop me a mail at koustuv.sinha@mail.mcgill.ca
Koustuv Sinha
Research Scientist
My research interests include natural language processing with machine learning, computational linguistics and interpretable machine learning. I organize the annual ML Reproducibility Challenge.