A workflow for reading, managing and discovering ML research papers with Emacs
Over the last couple of years I have steadily transferred most of my workflows in Emacs (more specifically, Doom Emacs). As they truly say, Emacs is not just an editor, it is an operating system. I think Emacs is not for everyone. It has a very steep learning curve, especially with understanding a new language (elisp) for configuration. Having said that, once you learn how to use Emacs, you unlock insane levels of productivity. It is customizable beyond expectation, and allows one to “live” within Emacs for most of their daily needs. Emacs has helped me streamline my paper reading habits, which I’ll talk in detail in this post. Specifically, I use the following tools from the Emacs ecosystem: Org-Mode, Elfeed, Elfeed-score, Helm-Bibtex and Org-ref.
Discovering papers: Elfeed
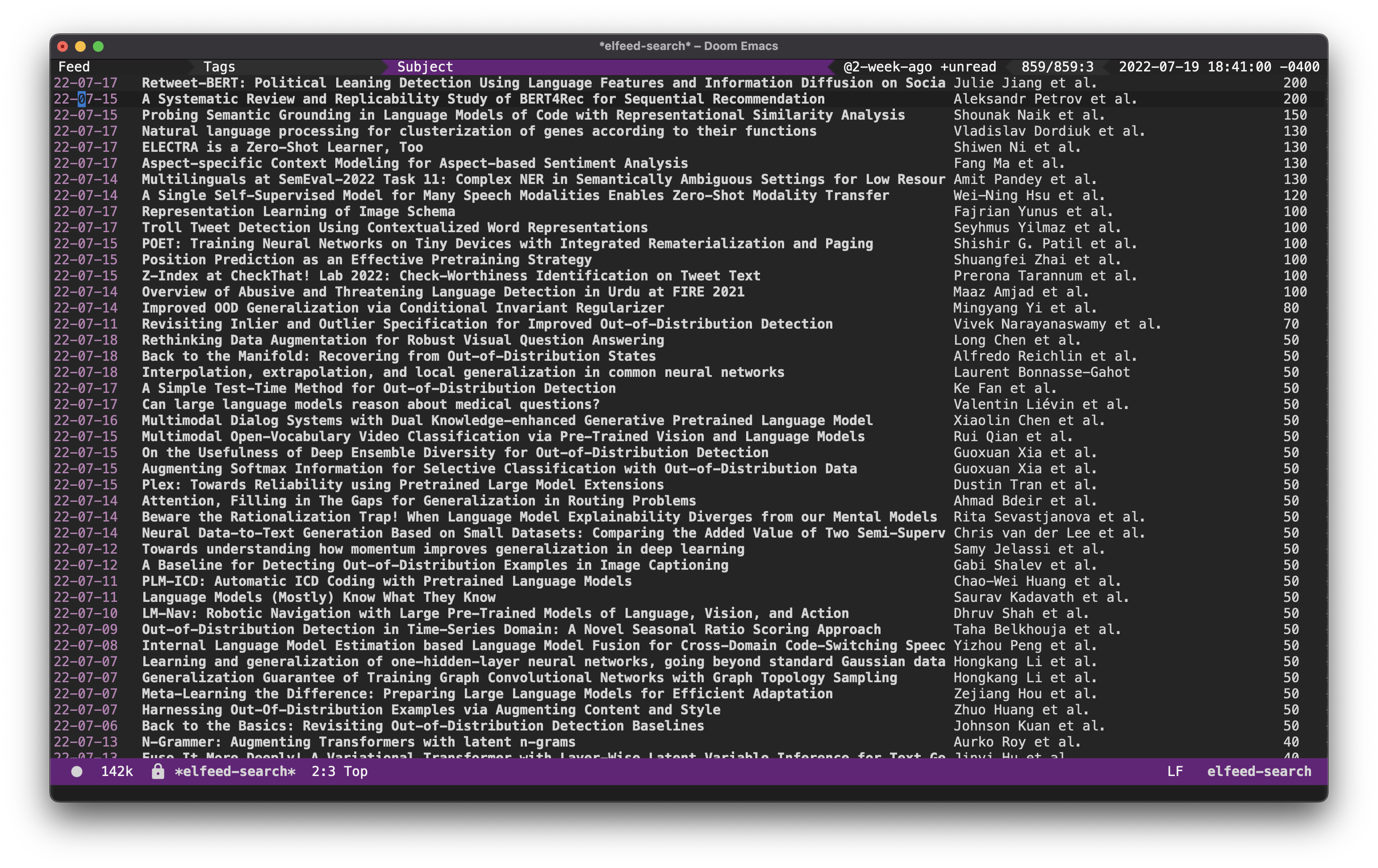
Elfeed is a very versatile RSS reader for Emacs. Turns out you can use Elfeed to subscribe to Arxiv feeds as well. Do check Chris Cundy’s post on this topic, where he introduces the concepts of Elfeed and Elfeed-score. Following the setup of Chris, I setup Elfeed to read Arxiv Atom posts in the stat.ML, cs.LG and cs.CL categories, which I typically follow anyways for new papers in NLP and ML.
The Basics
Setting up these Atom feeds in Elfeed is trivial.
(setq elfeed-feeds '("http://export.arxiv.org/api/query?search_query=cat:stat.ML&start=0&max_results=100&sortBy=submittedDate&sortOrder=descending" "http://export.arxiv.org/api/query?search_query=cat:cs.LG&start=0&max_results=100&sortBy=submittedDate&sortOrder=descending" "http://export.arxiv.org/api/query?search_query=cat:cs.CL&start=0&max_results=100&sortBy=submittedDate&sortOrder=descending"))
The elfeed-feeds variable consists of a list of strings with the export URLs. Notice in these URL’s the max_results are set to 100, feel free to modify it if you want to fetch older entries.
The default Elfeed homepage is not that useful for reading arxiv papers as it truncates the titles. Chris provides a nice solution to show the title and authors list truncated by an “et. al” in the main Elfeed view.
(defun concatenate-authors (authors-list)
"Given AUTHORS-LIST, list of plists; return string of all authors concatenated."
(if (> (length authors-list) 1)
(format "%s et al." (plist-get (nth 0 authors-list) :name))
(plist-get (nth 0 authors-list) :name)))
(defun my-search-print-fn (entry)
"Print ENTRY to the buffer."
(let* ((date (elfeed-search-format-date (elfeed-entry-date entry)))
(title (or (elfeed-meta entry :title)
(elfeed-entry-title entry) ""))
(title-faces (elfeed-search--faces (elfeed-entry-tags entry)))
(entry-authors (concatenate-authors
(elfeed-meta entry :authors)))
(title-width (- (window-width) 10
elfeed-search-trailing-width))
(title-column (elfeed-format-column
title 100
:left))
(entry-score (elfeed-format-column (number-to-string (elfeed-score-scoring-get-score-from-entry entry)) 10 :left))
(authors-column (elfeed-format-column entry-authors 40 :left)))
(insert (propertize date 'face 'elfeed-search-date-face) " ")
(insert (propertize title-column
'face title-faces 'kbd-help title) " ")
(insert (propertize authors-column
'kbd-help entry-authors) " ")
(insert entry-score " ")))
(setq elfeed-search-print-entry-function #'my-search-print-fn)
(setq elfeed-search-date-format '("%y-%m-%d" 10 :left))
(setq elfeed-search-title-max-width 110)
Then, set the default filter to show unread papers from 2 weeks ago. This is also customizable.
(setq elfeed-search-filter "@2-week-ago +unread")
We would also like to instruct Elfeed to fetch the papers whenever we open the Elfeed interface:
(add-hook! 'elfeed-search-mode-hook 'elfeed-update)
Scoring papers
As you may have noticed, my-search-print-fn contains the function elfeed-score-scoring-get-score-from-entry call, which uses Elfeed-score package to score individual papers. Elfeed-score is a simple but effective utility to allow you to set regex filter rules to score papers based on the relevance of your research area.
Install elfeed-score package using use-package, and then set the location of the rules file.
(use-package! elfeed-score
:after elfeed
:config
(elfeed-score-load-score-file "~/.doom.d/elfeed.score") ; See the elfeed-score documentation for the score file syntax
(elfeed-score-enable)
(define-key elfeed-search-mode-map "=" elfeed-score-map))
Now go ahead and create the file elfeed.score in your location of choice. This file basically contains the rules written in elisp. For example, my rule set after a couple of days usage is this:
;;; Elfeed score file -*- lisp -*-
((version 10)
("title"
(:text "Transformer" :value 10 :type s)
(:text "Summarization" :value -50 :type s))
("content")
("title-or-content"
(:text "Gender Bias" :title-value 50 :content-value 50 :type s)
(:text "BERT" :title-value 100 :content-value 50 :type S)
(:text "Generalization" :title-value 30 :content-value 20 :type s)
(:text "out-of-distribution" :title-value 20 :content-value 30 :type s)
(:text "language model" :title-value 20 :content-value 30 :type s))
("tag")
("authors"
(:text "Percy Liang" :value 200 :type w)
(:text "Sebastian Ruder" :value 200 :type w))
("feed")
("link")
("udf")
(mark nil)
("adjust-tags"))
This score file thus pushes the papers we would like to read up to the top:

Managing papers: Org-ref and Org-mode
When I’m reading the abstract of an interesting paper in Elfeed, if I want to read the pdf I can simply press Shift+RET to open the pdf in my browser. However, that doesn’t offer a way to store the pdf files, neither does it offer a way to open the pdf in emacs. I want a system which can allow me to:
- Store the pdf in a folder
- Add a bibtex entry to a centralized bib file with the paper information
- Keep track of papers I have read, along with notes
Store the pdfs from Elfeed
I initially started my configuration following the nice talk by Ahmed in EmacsConf 2021 (I highly recommend watching it!). Ahmed also provides a nice gist for starters, which I used to construct the basic function to perform steps 1 and 2.
(setq arxiv_bib "~/org/arxiv.bib")
(setq arxiv_pdf_loc "~/Documents/arxiv/")
(defun my/elfeed-entry-to-arxiv ()
"Fetch an arXiv paper into the local library from the current elfeed entry.
"
(interactive)
(let* ((link (elfeed-entry-link elfeed-show-entry))
(match-idx (string-match "arxiv.org/abs/\\([0-9.]*\\)" link))
(matched-arxiv-number (match-string 1 link)))
(when matched-arxiv-number
(message "Going to arXiv: %s" matched-arxiv-number)
(arxiv-get-pdf-add-bibtex-entry matched-arxiv-number arxiv_bib arxiv_pdf_loc))
This function utilizes the awesome Org-ref library functions, such as arxiv-get-pdf-add-bibtex-entry. Given an Arxiv identifier, this function firsts constructs a bibtex entry with the paper metadata and stores it in arxiv_bib, which is a variable I had set to point to my centralized bib file. Then, the function downloads the pdf, renames the pdf to the bibtex key, and saves it in arxiv_pdf_loc, which is another variable I had defined which points to the directory where I want to save the pdfs.
We can add a Doom Emacs keybinding to quickly fetch the arxiv file. This allows me to call SPC n a from the Elfeed entry buffer.
(map! :leader
:desc "arXiv paper to library" "n a" #'my/elfeed-entry-to-arxiv
:desc "Elfeed" "n e" #'elfeed)
Update the bibtex file
The bibtex generated by the arxiv-get-pdf-add-bibtex-entry function lacks a file item pointing to the pdf file. We will see why this item is useful in the next section. Assuming we need to add the full path of the downloaded pdf, the my/elfeed-entry-to-arxiv function can be modified as follows:
(defun my/elfeed-entry-to-arxiv ()
"Fetch an arXiv paper into the local library from the current elfeed entry.
- Update the bib entry with the pdf file location
"
(interactive)
(let* ((link (elfeed-entry-link elfeed-show-entry))
(match-idx (string-match "arxiv.org/abs/\\([0-9.]*\\)" link))
(matched-arxiv-number (match-string 1 link)))
(when matched-arxiv-number
(message "Going to arXiv: %s" matched-arxiv-number)
(arxiv-get-pdf-add-bibtex-entry matched-arxiv-number arxiv_bib arxiv_pdf_loc)
;; Now, we are updating the most recent bib file with the pdf location
(save-window-excursion
;; Get the bib file
(find-file arxiv_bib)
;; get to last line
(goto-char (point-max))
;; get to the first line of bibtex
(bibtex-beginning-of-entry)
(let* ((entry (bibtex-parse-entry))
(key (cdr (assoc "=key=" entry)))
(pdf (org-ref-get-pdf-filename key)))
(message (concat "checking for key: " key))
(message (concat "value of pdf: " pdf))
(when (file-exists-p pdf)
(bibtex-set-field "file" pdf)
(save-buffer)
)))
)
)
)
(setq org-ref-pdf-directory arxiv_pdf_loc)
What this function does is it opens the bibfile (arxiv_bib), navigates to the last line, then again navigates to the first line of the last bibtex entry to load the bibtex, and then fetches the pdf path. Then the function adds a file field to the bibtex with the pdf path using the function bibtex-set-field.
It is also important to set the path of org-ref-pdf-directory variable to the location of your pdf files, for org-ref to fetch the full path of the pdf properly using org-ref-get-pdf-filename function.
Tracking a reading list
Now I have the mechanisms in place to store the pdf and the bibtex entries of the papers I want to read after looking through the latest arxiv posts. This is a good time to setup a workflow to track my paper reading lists. I use Org-mode for this purpose.
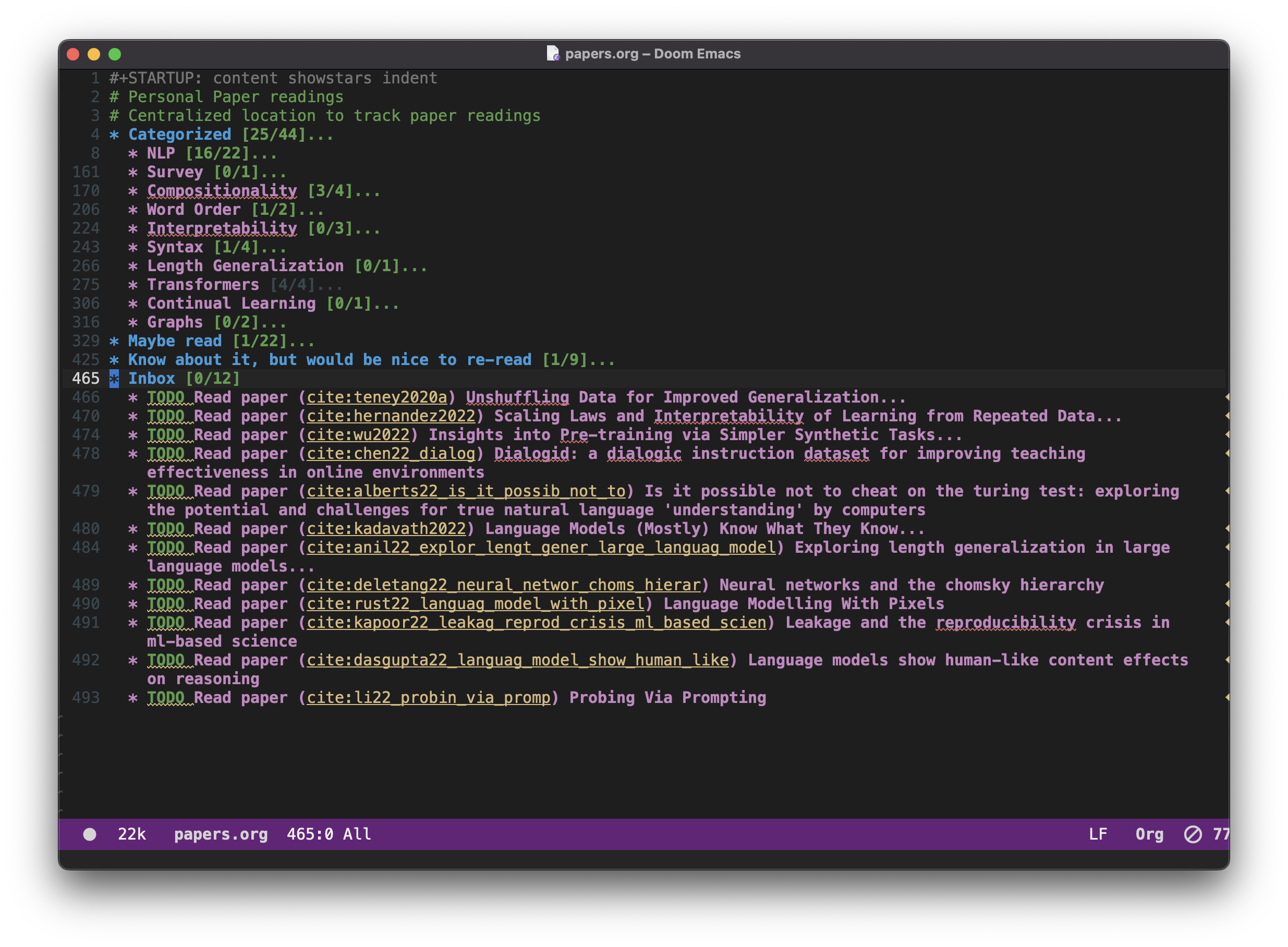
Specifically, I create an Org file named papers.org, which has the following structure:
#+STARTUP: content showstars indent
# Personal Paper readings
# Centralized location to track paper readings
* Categorized [/]
:PROPERTIES:
:COOKIE_DATA: recursive todo
:END:
** Some specific subfield
* Maybe Read [/]
* Know about it, would be nice to re-read [/]
* Inbox
These are basically headings to file TODO items. I keep track of a paper to read using the Org TODO modes. For any new paper which I’m reading through Elfeed, I hit SPC n e to extract the bibtex and save the pdf in the centralized pdf directory. Now, I would want to file this paper automatically under * Inbox header as a TODO entry. To do that, we can modify the above function to read papers.org, go to the last element of the page (which points to the latest filed paper in * Inbox), and add a new entry with Org-ref citation.
(defun my/elfeed-entry-to-arxiv ()
"Fetch an arXiv paper into the local library from the current elfeed entry.
This is a customized version from the one in https://gist.github.com/rka97/57779810d3664f41b0ed68a855fcab54
New features to this version:
- Update the bib entry with the pdf file location
- Add a TODO entry in my papers.org to read the paper
"
(interactive)
(let* ((link (elfeed-entry-link elfeed-show-entry))
(match-idx (string-match "arxiv.org/abs/\\([0-9.]*\\)" link))
(matched-arxiv-number (match-string 1 link))
(last-arxiv-key "")
(last-arxiv-title ""))
(when matched-arxiv-number
(message "Going to arXiv: %s" matched-arxiv-number)
(arxiv-get-pdf-add-bibtex-entry matched-arxiv-number arxiv_bib arxiv_pdf_loc)
;; Now, we are updating the most recent bib file with the pdf location
(message "Update bibtex with pdf file location")
(save-window-excursion
;; Get the bib file
(find-file arxiv_bib)
;; get to last line
(goto-char (point-max))
;; get to the first line of bibtex
(bibtex-beginning-of-entry)
(let* ((entry (bibtex-parse-entry))
(key (cdr (assoc "=key=" entry)))
(title (bibtex-completion-apa-get-value "title" entry))
(pdf (org-ref-get-pdf-filename key)))
(message (concat "checking for key: " key))
(message (concat "value of pdf: " pdf))
(when (file-exists-p pdf)
(bibtex-set-field "file" pdf)
(setq last-arxiv-key key)
(setq last-arxiv-title title)
(save-buffer)
)))
;; (message (concat "outside of save window, key: " last-arxiv-key))
;; Add a TODO entry with the cite key and title
;; This is a bit hacky solution as I don't know how to add the org entry programmatically
(save-window-excursion
(find-file (concat org-directory "papers.org"))
(goto-char (point-max))
(insert (format "** TODO Read paper (cite:%s) %s" last-arxiv-key last-arxiv-title))
(save-buffer)
)
)
)
)
Thus we arrive at the final version of the my/elfeed-entry-to-arxiv function, which is now modified to keep track of the key of the paper using last-arxiv-key and title of the paper last-arxiv-title, so that we can construct a TODO entry to reflect the key and the title. The key is added in Org citation format.
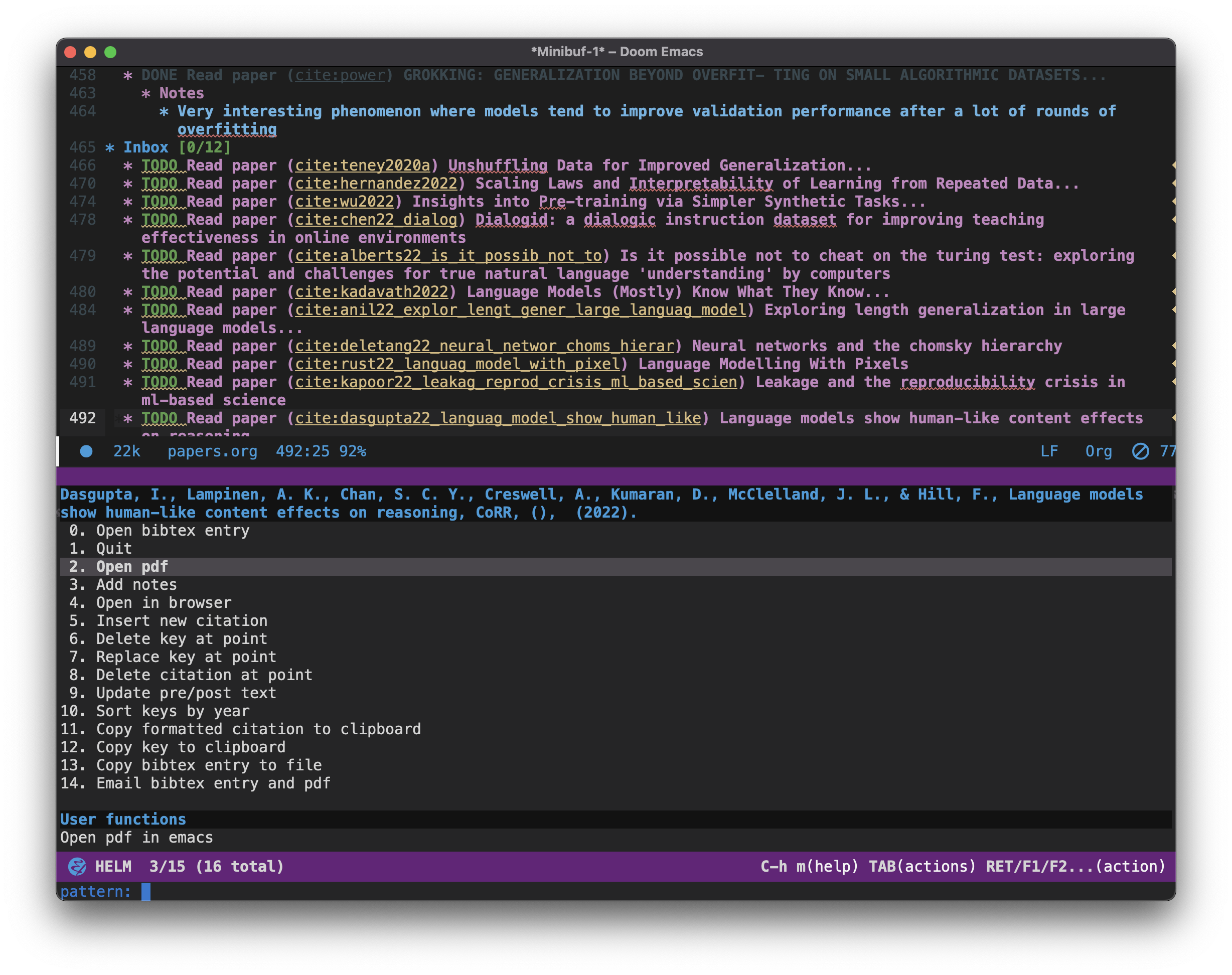
I use helm-bibtex as my completion engine for bibtex, which shows me a menu when I RET on the citation key. Helm-bibtex allows me to see a contextual menu on any org link. I need to set the following variables so that helm-bibtex knows where to look for the pdf files:
(setq bibtex-completion-bibliography (list arxiv_bib))
(setq bibtex-completion-pdf-field "file")
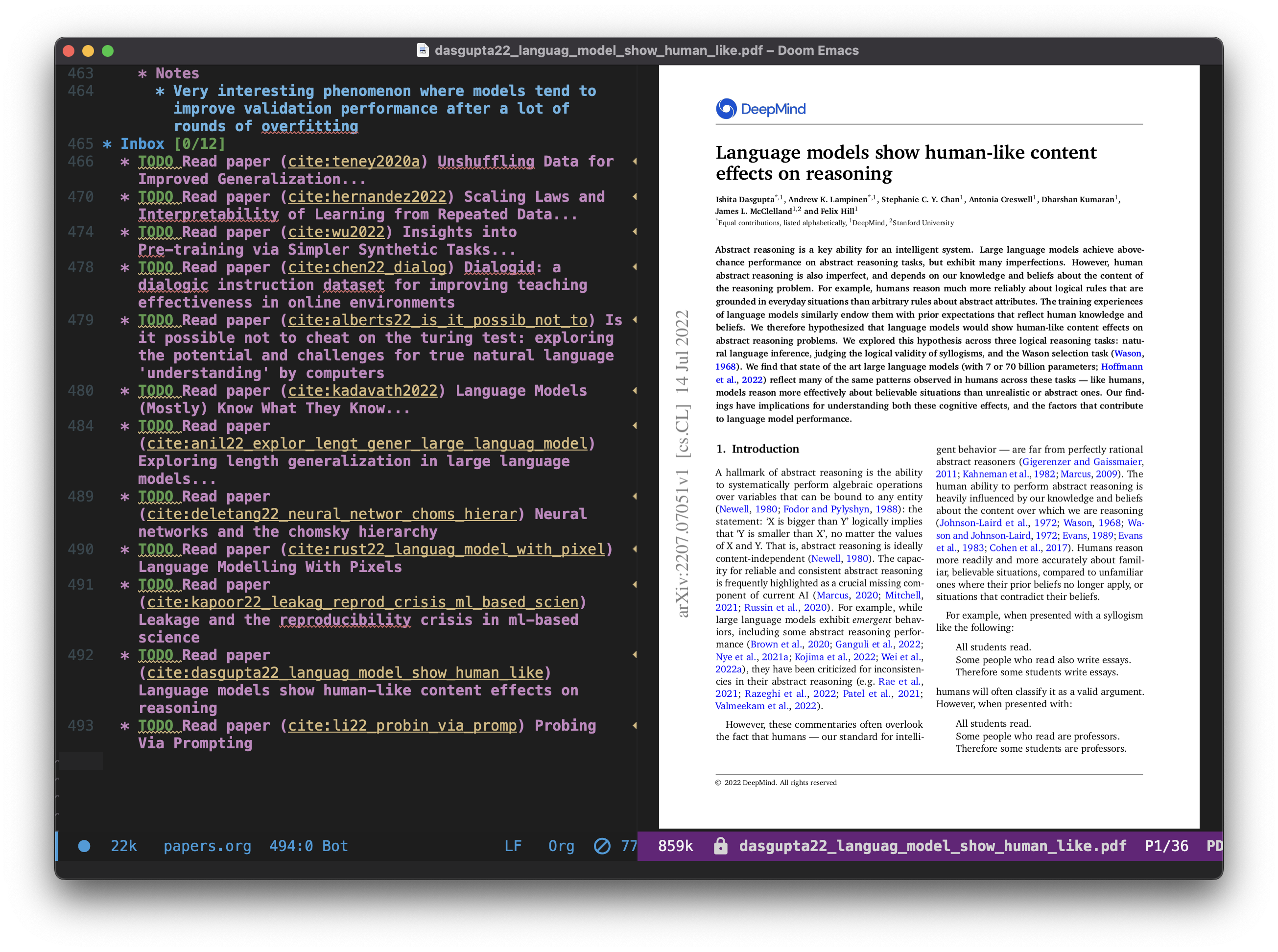
Thus, using Org-mode to track my paper reading list helps me to store all my reading habits and notes within one file!
- I use the
* Inboxheader as a staging area whenever I store a paper from Elfeed. - After I store the paper, I can re-file the paper in several categories as defined in
papers.org, easily, usingC-c C-w. - I can read the paper directly in Emacs by
RET -> Open PDF -> RET! - The
[/]is a TODO status indicator used in front of every header, which shows me the number of read papers out of total number of papers in the sub-heading. Whenever I read the paper, I can just hitRETon the paper header to change the status toDONE, which automatically increases the count! - I can directly use this org file to take notes under the header of each paper.
This workflow allows me to seamlessly fetch, read and take notes on papers, fully keyboard driven, directly inside one app!
Syncing & Note taking in Ipad
Using the above method makes it trivial to sync my reading lists on my Apple Ipad. For starters, I keep the org files and bib files in my Dropbox directory, so any change in the papers.org file gets synced through Dropbox. I also add the arxiv pdf directory in my Dropbox, so that any new pdfs are automatically synced throughout my devices. On my Ipad, I use PDF Expert to read and annotate the papers by linking my Dropbox account. I take copious scribbles using my Apple pencil, and they are immediately synced so I can view the annotated pdf directly from my papers.org file.
Closing Thoughts
This is an evolving workflow, and it is probably not the most optimal one. However it works for me, and I can easily keep tweaking the config so that it supports any future requirements. Let me know if this worked for you in the comments, and I would love to hear any suggestions you might have so that I can make this workflow better! Thanks for reading!
Koustuv Sinha
Research Scientist
My research interests include natural language processing with machine learning, computational linguistics and interpretable machine learning. I organize the annual ML Reproducibility Challenge.