GraphLog - Suite of 57 graph worlds built using first-order logic
Koustuv Sinha, Shagun Sodhani, Joelle Pineau and William L. Hamilton
Code | Docs | Paper | Home Page | Teaser Talk
Motivation
A question that we are highly interested in finding an answer to is how generalizable our learning algorithms are? Human beings are incredibly good at generalization - even at old age, we can learn new concepts and apply them in practice. Critical steps towards building algorithms that think like human beings include Multitask Learning - the ability to learn multiple concepts at once; and Continual Learning - the ability to accumulate new knowledge without forgetting the previous knowledge.
Defining a task that aims at either Multitask Learning or Continual learning is challenging - the task should accurately quantify the “distribution shift” in the data. Having precise control of this shift could allow us to understand the drawbacks of our learning methods, and build systems which can generalize over multiple tasks but still remember the old ones.
Data distributions can be quantified by generating them based on a
grammar. First-order logic, even with its basic use-case and
restrictions, can be an excellent tool for defining such generalizable
distributions - to test how systematic a model is. In our prior work, we
leveraged first-order logic to build the
CLUTRR dataset, which
provides a kinship-relation game in natural language QA setting. A nice
property of CLUTRR is that it is designed to be a dynamic dataset -
one can always roll out longer kinship relation trees to stress-test the
generalizability of their proposed approach. Since it is designed to be
diagnostic, it opens up the possibility of investigating the semantic
understanding capability of Natural Language Understanding models under
microscopic
precision.
While CLUTRR primarily investigates the aspect of length generalization, the core semantic rules driving the kinship relations are static. In a real-world scenario, a model may have to adapt to the change in underlying dynamics of the domain (for example, recommender systems trained on one domain being deployed / finetuned on a new domain). In terms of grammar, two domains sharing the same grammar constitute similar domains. We need a task where we can generalize over different grammars and control the amount of distribution shift.
Introducing GraphLog
In this work, we introduce a new paradigm of testing domain
generalization in graph-structure data, named GraphLog. Instead of
being a single dataset, GraphLog v1.0 contains 57 datasets, which
have their own set of grammar or generation rules.
The Task : We are primarily interested in relation prediction, where given a graph \(gi\), a source node \(v_i\), and sink node \(v_j\), the task is to predict the _type of the edge \(r\) between \((v_i, v_j)\). In Graph Neural Network (GNN) world, this task is typically performed by RGCN model on popular relation prediction datasets.
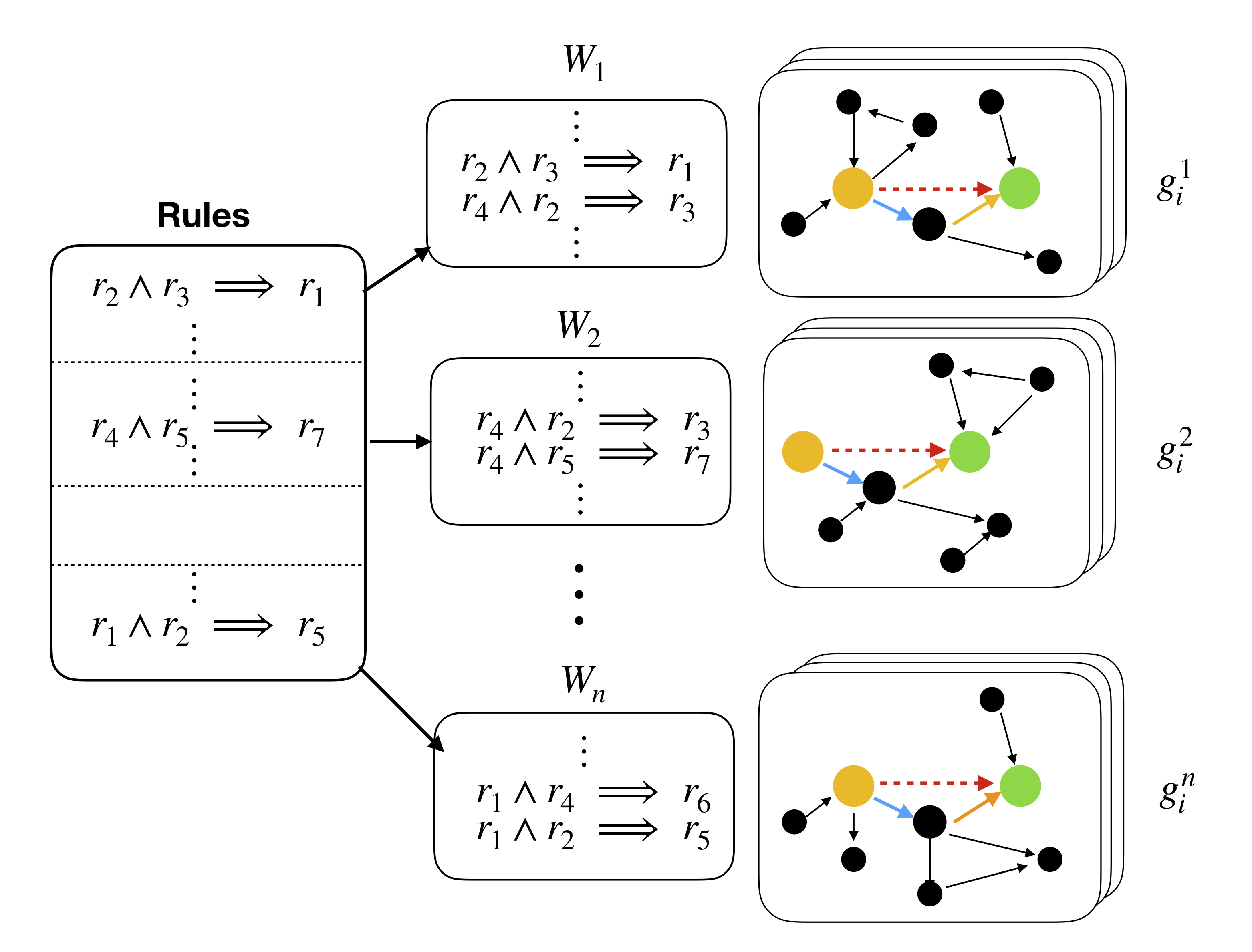
Graphs in GraphLog are generated using rules in first-order logic.
These rules are 2-ary Horn clauses in the form of
\([r_i, r_j] \rightarrow rj\), where \(r_i\) are the _types of
relation. Each world is a dataset on its own, which consists of 5000
graphs procedurally generated by their own set of rules, which
themselves are generated stochastically. Between multiple worlds, there
can be overlap between the rules, which helps us in explicitly
quantifying the shift in the data distribution. This enables us to
perform Multi-task learning and Continual learning along with supervised
learning experiments in graph-structured data, which is one of the first
datasets which propose to do so.
| Dataset | Inspectable Rules | Diversity | Compositional Generalization | Modality | S | Me | Mu | CL |
|---|---|---|---|---|---|---|---|---|
| CLEVR | :white_check_mark: | :x: | :x: | Vision | :white_check_mark: | :x: | :x: | :x: |
| Cogent | :white_check_mark: | :x: | :white_check_mark: | Vision | :white_check_mark: | :x: | :x: | :x: |
| CLUTRR | :white_check_mark: | :x: | :white_check_mark: | Text | :white_check_mark: | :x: | :x: | :x: |
| SCAN | :white_check_mark: | :x: | :white_check_mark: | Text | :white_check_mark: | :white_check_mark: | :x: | :x: |
| SQoOP | :white_check_mark: | :x: | :white_check_mark: | Vision | :white_check_mark: | :x: | :x: | :x: |
| TextWorld | :x: | :white_check_mark: | :white_check_mark: | Text | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| GraphLog | :white_check_mark: | :white_check_mark: | :white_check_mark: | Graph | :white_check_mark: | :white_check_mark: | :white_check_mark: | :white_check_mark: |
Supervised Learning
GraphLog can be used to perform supervised relation prediction tasks
in any of its multiple worlds. Due to the stochastic nature of rule
generation, certain worlds are more difficult than others. We define
the notion of difficulty empirically based on model performance, but we
observe a correlation with the number of descriptors or unique walks
in the graphs associated with a world.
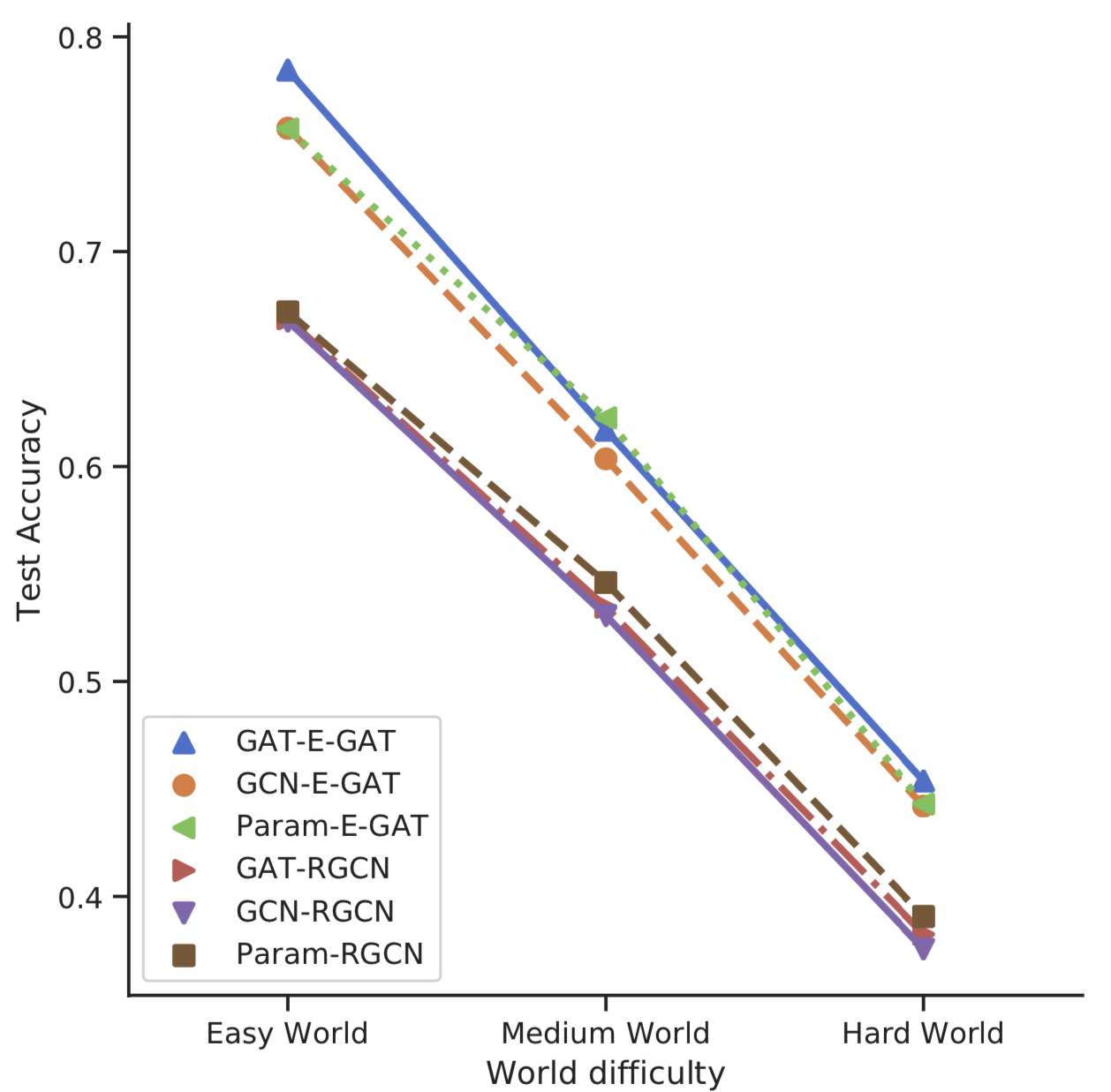
Multi-task Learning
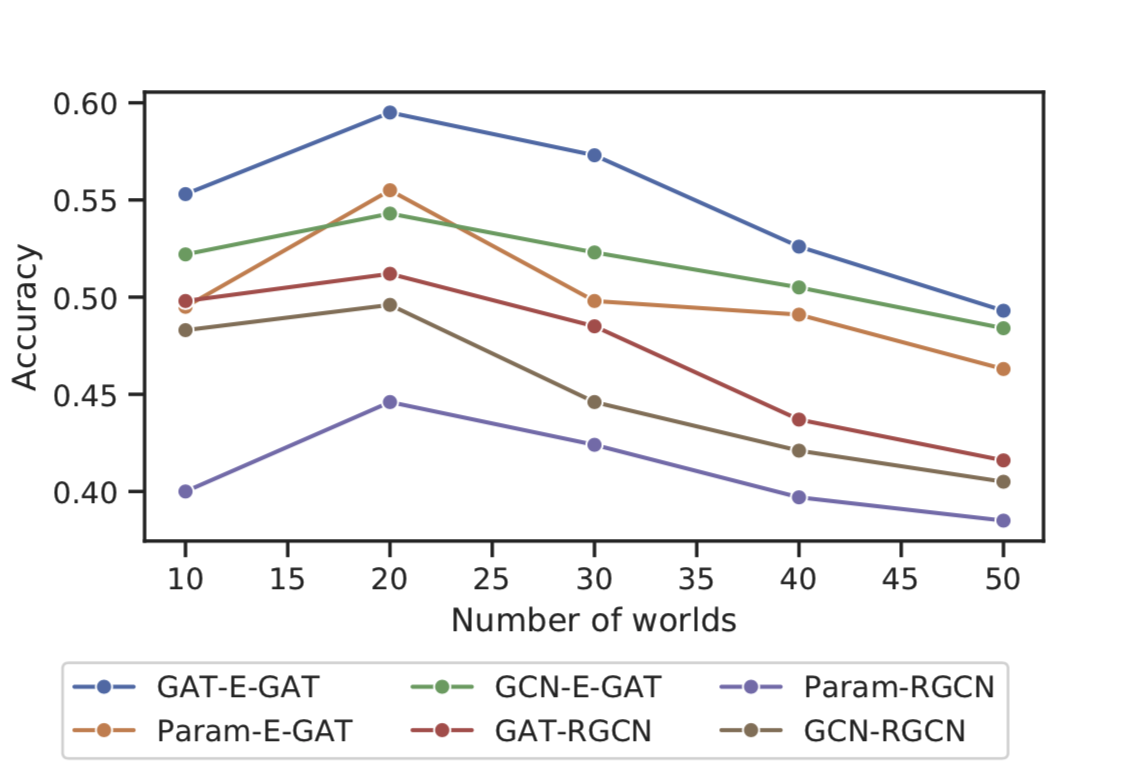
GraphLog makes it easy to extend the supervised learning framework
for multi-task learning by transferring model parameters on the next
task. We find the model’s capacity saturates at 20 tasks, however we
hypothesize larger capacity with more data points will increase the
number of tasks. We use a two-step model that adapts for relations in
different worlds, the details of which can be
found in our paper.
Continual Learning
GraphLog enables us to evaluate the generalization capability of
graph neural networks in the sequential continual learning setup where
the model is trained on a sequence of worlds. Before training on a new
world, the model is evaluated on all the worlds that the model has
trained on so far. We observe that as the model is trained on different
worlds, it performance on the previous worlds degrades rapidly. This
observation highlights that the current reasoning models are not
suitable for continual learning.
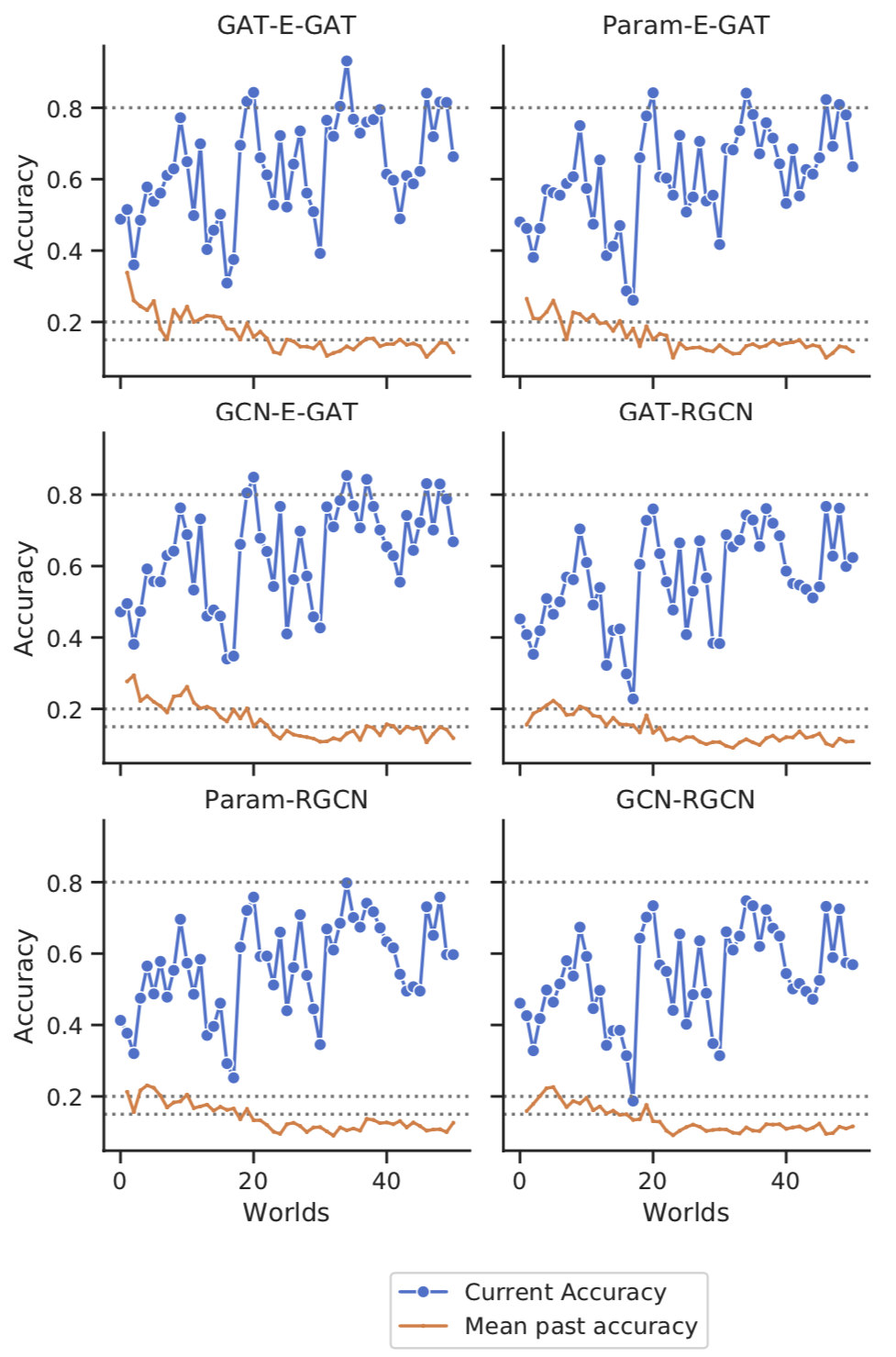
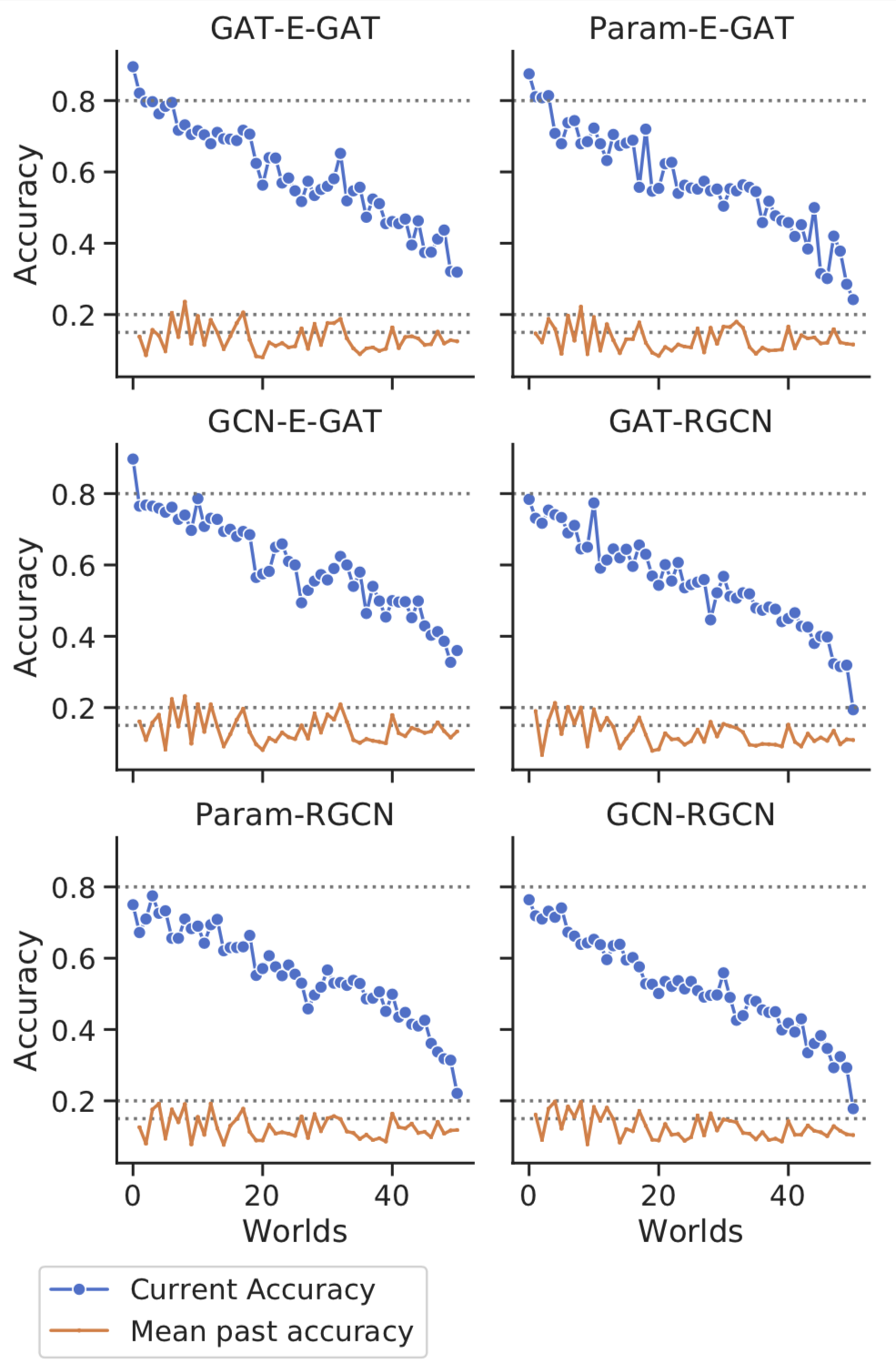
Experiments on sequential continual learning setting. The first image depicts random ordering, and the second image depicts ordering based on world difficulty.
Using GraphLog
We hope that the above examples got you excited about the possibilities
of GraphLog! We have made it easier for you to play with
GraphLog v1.0 by releasing an
API on PyPi, graphlog, which
provides custom dataloaders built on
Pytorch Geometric.
We have released the code for the API at https://github.com/facebookresearch/graphlog, which includes basic and advanced use cases, as well as simple examples built on Pytorch Lightning. We will be releasing the code to generate GraphLog soon as well, so you can build your own version of GraphLog and contribute to the repository.
I want to read more
This blog post provides a summary of the results and basic use cases of
GraphLog. Please read more in our paper on arxiv titled
Evaluating Logical Generalization
in Graph Neural Networks. Our submission is currently under review at
ICML 2020. The code for reproducing the main experiments are now
available in the
GraphLog
repository.
If you have any questions regarding the usage of GraphLog, feel free
to open an
issue, or join our
Slack
Channel, or send me a mail at
koustuv.sinha@mail.mcgill.ca.
If you would like to contribute, do
open a Pull
Request (PR)!.
Acknowledgements
I would like to thank my collaborator Shagun Sodhani for not only helping in writing this blog post, but for being a constant source of motivation throughout our various adventures in research. I would also like to thank my amazing supervisors, William L. Hamilton and Joelle Pineau, for their constant motivation and support. I am grateful to Facebook AI Research (FAIR) for providing extensive compute resources to make this project possible. I thank my wonderful colleagues at Mila and FAIR for various constructive feedback on the project. This research was supported by the Canada CIFAR Chairs in AI program.