Abstract
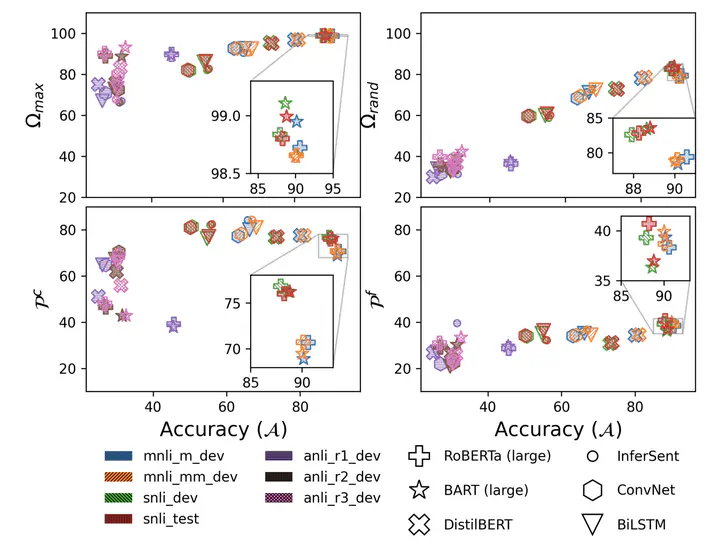
Recent investigations into the inner-workings of state-of-the-art large-scale pre-trained Transformer-based Natural Language Understanding (NLU) models indicate that they appear to understand human-like syntax, at least to some extent. We provide novel evidence that complicates this claim: we find that state-of-the-art Natural Language Inference (NLI) models assign the same labels to permuted examples as they do to the original, i.e. they are invariant to random word-order permutations. This behavior notably differs from that of humans; we struggle to understand the meaning of ungrammatical sentences. To measure the severity of this issue, we propose a suite of metrics and investigate which properties of particular permutations lead models to be word order invariant. For example, in MNLI dataset we find almost all (98.7%) examples contain at least one permutation which elicits the gold label. Models are even able to assign gold labels to permutations that they originally failed to predict correctly. We provide a comprehensive empirical evaluation of this phenomenon, and further show that this issue exists in pre-Transformer RNN / ConvNet based encoders, as well as across multiple languages (English and Chinese). Our code and data are available at https://github.com/facebookresearch/unlu.

Latest News
- July 3, 2021 : We are honored to be awarded Outstanding Paper Award in ACL-IJCNLP 2021!
Koustuv Sinha
Research Scientist
My research interests include natural language processing with machine learning, computational linguistics and interpretable machine learning. I organize the annual ML Reproducibility Challenge.